Using the class Table() for data analysis
Say we have previously renamed the EPW files with rename_epw_files(), and the EPWs we currently have are:
United-Kingdom_Aberdeen_Present
United-Kingdom_London_Present
We also have transformed the IDF file TestModel_onlyGeometryForVRFsystem_2zones_CalcVent_V2220.idf, and the IDFs we currently have are:
TestModel[CS_INT EN16798[CA_1[CM_0[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X.idf
TestModel[CS_INT EN16798[CA_1[CM_3[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X.idf
TestModel[CS_INT EN16798[CA_2[CM_0[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X.idf
TestModel[CS_INT EN16798[CA_2[CM_3[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X.idf
TestModel[CS_INT EN16798[CA_3[CM_0[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X.idf
TestModel[CS_INT EN16798[CA_3[CM_3[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X.idf
Next, we simulate these files with runEp(), so the CSVs we get are:
[1]:
import os
print(*[i for i in os.listdir() if i.endswith('.csv') and 'TestModel' in i], sep='\n')
TestModel[CS_INT EN16798[CA_1[CM_0[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_Aberdeen_Present.csv
TestModel[CS_INT EN16798[CA_1[CM_0[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_London_Present.csv
TestModel[CS_INT EN16798[CA_1[CM_3[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_Aberdeen_Present.csv
TestModel[CS_INT EN16798[CA_1[CM_3[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_London_Present.csv
TestModel[CS_INT EN16798[CA_2[CM_0[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_Aberdeen_Present.csv
TestModel[CS_INT EN16798[CA_2[CM_0[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_London_Present.csv
TestModel[CS_INT EN16798[CA_2[CM_3[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_Aberdeen_Present.csv
TestModel[CS_INT EN16798[CA_2[CM_3[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_London_Present.csv
TestModel[CS_INT EN16798[CA_3[CM_0[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_Aberdeen_Present.csv
TestModel[CS_INT EN16798[CA_3[CM_0[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_London_Present.csv
TestModel[CS_INT EN16798[CA_3[CM_3[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_Aberdeen_Present.csv
TestModel[CS_INT EN16798[CA_3[CM_3[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_London_Present.csv
Let’s see which are our initial files to not to delete them later.
[2]:
previous_files = [i for i in os.listdir()]
So now, let’s use the class Table() to analyse the data.
1. Getting the full dataset of simulation results
[3]:
from accim.data.postprocessing.main import Table
dataset_hourly = Table(
#datasets=list #Since we are not specifying any list, it will use all available CSVs in the folder
source_frequency='hourly', # This lets accim know which is the frequency of the input CSVs. Input CSVs with multiple frequencies are also allowed. It can be 'hourly', 'daily', 'monthly' and 'runperiod'. It can also be 'timestep' but might generate errors.
frequency='hourly', # If 'daily', accim will aggregate the rows in days. It can be 'hourly', 'daily', 'monthly' and 'runperiod'. It can also be 'timestep' but might generate errors.
frequency_agg_func='sum', #this makes the sum or average when aggregating in days, months or runperiod; since the original CSV frequency is in hour, it won't make any aeffect
standard_outputs=True,
level=['building'], # A list containing the strings 'block' and/or 'building'. For instance, if ['block', 'building'], accim will generate new columns to sum up or average in blocks and building level.
level_agg_func=['sum', 'mean'], # A list containing the strings 'sum' and/or 'mean'. For instance, if ['sum', 'mean'], accim will generate the new columns explained in the level argument by summing and averaging.
level_excluded_zones=[],
split_epw_names=True, #to split EPW names based on the pattern Country_City_RCPscenario-Year
idf_path='TestModel[CS_INT EN16798[CA_1[CM_0[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X.idf', # Any of the simulated IDFs, considering all of these are the same building and therefore have the same zones. Used to scan the zones and identify them in the CSVs.
)
Input data frequency in file TestModel[CS_INT EN16798[CA_1[CM_0[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_Aberdeen_Present.csv is hourly, therefore no aggregation will be performed.
Input data frequency in file TestModel[CS_INT EN16798[CA_1[CM_0[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_London_Present.csv is hourly, therefore no aggregation will be performed.
Input data frequency in file TestModel[CS_INT EN16798[CA_1[CM_3[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_Aberdeen_Present.csv is hourly, therefore no aggregation will be performed.
Input data frequency in file TestModel[CS_INT EN16798[CA_1[CM_3[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_London_Present.csv is hourly, therefore no aggregation will be performed.
Input data frequency in file TestModel[CS_INT EN16798[CA_2[CM_0[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_Aberdeen_Present.csv is hourly, therefore no aggregation will be performed.
Input data frequency in file TestModel[CS_INT EN16798[CA_2[CM_0[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_London_Present.csv is hourly, therefore no aggregation will be performed.
Input data frequency in file TestModel[CS_INT EN16798[CA_2[CM_3[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_Aberdeen_Present.csv is hourly, therefore no aggregation will be performed.
Input data frequency in file TestModel[CS_INT EN16798[CA_2[CM_3[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_London_Present.csv is hourly, therefore no aggregation will be performed.
Input data frequency in file TestModel[CS_INT EN16798[CA_3[CM_0[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_Aberdeen_Present.csv is hourly, therefore no aggregation will be performed.
Input data frequency in file TestModel[CS_INT EN16798[CA_3[CM_0[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_London_Present.csv is hourly, therefore no aggregation will be performed.
Input data frequency in file TestModel[CS_INT EN16798[CA_3[CM_3[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_Aberdeen_Present.csv is hourly, therefore no aggregation will be performed.
Input data frequency in file TestModel[CS_INT EN16798[CA_3[CM_3[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_London_Present.csv is hourly, therefore no aggregation will be performed.
No zones have been excluded from level computations.
All CSVs are for present scenario.
A Table object has been created, which includes a number of accessible variables. The most important is the Pandas Dataframe created from the CSVs, which can be accessed with .df (in this case, dataset_hourly.df)
[4]:
dataset_hourly.df
[4]:
| Source | Model | ComfStand | CAT | ComfMod | HVACmode | VentCtrl | VSToffset | MinOToffset | MaxWindSpeed | ... | Building_Total_Heating Energy Demand (kWh/m2) (summed) | Building_Total_Heating Energy Demand (kWh/m2) (mean) | Building_Total_Cooling Energy Consumption (kWh/m2) (summed) | Building_Total_Cooling Energy Consumption (kWh/m2) (mean) | Building_Total_Heating Energy Consumption (kWh/m2) (summed) | Building_Total_Heating Energy Consumption (kWh/m2) (mean) | Building_Total_Total Energy Demand (kWh/m2) (summed) | Building_Total_Total Energy Demand (kWh/m2) (mean) | Building_Total_Total Energy Consumption (kWh/m2) (summed) | Building_Total_Total Energy Consumption (kWh/m2) (mean) | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | TestModel[CS_INT EN16798[CA_1[CM_0[HM_2[VC_0[V... | TestModel | CS_INT EN16798 | CA_1 | CM_0 | HM_2 | VC_0 | VO_0 | MT_50 | MW_50 | ... | 0.036738 | 0.018369 | 0.0 | 0.0 | 0.030576 | 0.015288 | 0.036738 | 0.009185 | 0.030576 | 0.007644 |
| 1 | TestModel[CS_INT EN16798[CA_1[CM_0[HM_2[VC_0[V... | TestModel | CS_INT EN16798 | CA_1 | CM_0 | HM_2 | VC_0 | VO_0 | MT_50 | MW_50 | ... | 0.040240 | 0.020120 | 0.0 | 0.0 | 0.034616 | 0.017308 | 0.040240 | 0.010060 | 0.034616 | 0.008654 |
| 2 | TestModel[CS_INT EN16798[CA_1[CM_0[HM_2[VC_0[V... | TestModel | CS_INT EN16798 | CA_1 | CM_0 | HM_2 | VC_0 | VO_0 | MT_50 | MW_50 | ... | 0.042701 | 0.021350 | 0.0 | 0.0 | 0.037389 | 0.018695 | 0.042701 | 0.010675 | 0.037389 | 0.009347 |
| 3 | TestModel[CS_INT EN16798[CA_1[CM_0[HM_2[VC_0[V... | TestModel | CS_INT EN16798 | CA_1 | CM_0 | HM_2 | VC_0 | VO_0 | MT_50 | MW_50 | ... | 0.044282 | 0.022141 | 0.0 | 0.0 | 0.039079 | 0.019539 | 0.044282 | 0.011071 | 0.039079 | 0.009770 |
| 4 | TestModel[CS_INT EN16798[CA_1[CM_0[HM_2[VC_0[V... | TestModel | CS_INT EN16798 | CA_1 | CM_0 | HM_2 | VC_0 | VO_0 | MT_50 | MW_50 | ... | 0.045109 | 0.022554 | 0.0 | 0.0 | 0.039927 | 0.019964 | 0.045109 | 0.011277 | 0.039927 | 0.009982 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 105115 | TestModel[CS_INT EN16798[CA_3[CM_3[HM_2[VC_0[V... | TestModel | CS_INT EN16798 | CA_3 | CM_3 | HM_2 | VC_0 | VO_0 | MT_50 | MW_50 | ... | 0.011349 | 0.005675 | 0.0 | 0.0 | 0.007941 | 0.003970 | 0.011349 | 0.002837 | 0.007941 | 0.001985 |
| 105116 | TestModel[CS_INT EN16798[CA_3[CM_3[HM_2[VC_0[V... | TestModel | CS_INT EN16798 | CA_3 | CM_3 | HM_2 | VC_0 | VO_0 | MT_50 | MW_50 | ... | 0.011955 | 0.005978 | 0.0 | 0.0 | 0.008373 | 0.004186 | 0.011955 | 0.002989 | 0.008373 | 0.002093 |
| 105117 | TestModel[CS_INT EN16798[CA_3[CM_3[HM_2[VC_0[V... | TestModel | CS_INT EN16798 | CA_3 | CM_3 | HM_2 | VC_0 | VO_0 | MT_50 | MW_50 | ... | 0.012974 | 0.006487 | 0.0 | 0.0 | 0.009094 | 0.004547 | 0.012974 | 0.003243 | 0.009094 | 0.002273 |
| 105118 | TestModel[CS_INT EN16798[CA_3[CM_3[HM_2[VC_0[V... | TestModel | CS_INT EN16798 | CA_3 | CM_3 | HM_2 | VC_0 | VO_0 | MT_50 | MW_50 | ... | 0.015072 | 0.007536 | 0.0 | 0.0 | 0.010571 | 0.005286 | 0.015072 | 0.003768 | 0.010571 | 0.002643 |
| 105119 | TestModel[CS_INT EN16798[CA_3[CM_3[HM_2[VC_0[V... | TestModel | CS_INT EN16798 | CA_3 | CM_3 | HM_2 | VC_0 | VO_0 | MT_50 | MW_50 | ... | 0.017182 | 0.008591 | 0.0 | 0.0 | 0.012108 | 0.006054 | 0.017182 | 0.004295 | 0.012108 | 0.003027 |
105120 rows × 111 columns
[5]:
dataset_hourly.df.shape
[5]:
(105120, 111)
Also, you can see the block list that has been extracted from the zones in the CSV columns, as well as the zones with heating or cooling energy consumption, and the occupied zones:
[6]:
dataset_hourly.block_list
[6]:
['Block1']
[7]:
dataset_hourly.hvac_zone_list
[7]:
['Block1:Zone2', 'Block1:Zone1']
[8]:
dataset_hourly.occupied_zone_list
[8]:
['Block1:Zone1', 'Block1:Zone2']
In case of lots of CSVs, using the Table class would mean gathering the CSVs to make the Dataframe each time, and it might be very time-consuming. Therefore, the CSVs can be concatenated into a single CSV and store in the same folder with the argument concatenated_csv_name. Afterwards, that concatenated CSV can be read using the argument source_concatenated_csv_filepath each time a Table class object is created.
[9]:
concatenated_csvname = 'notebook_example'
dataset_hourly_indirect = Table(
#datasets=list #Since we are not specifying any list, it will use all available CSVs in the folder
source_frequency='hourly', # This lets accim know which is the frequency of the input CSVs. Input CSVs with multiple frequencies are also allowed. It can be 'hourly', 'daily', 'monthly' and 'runperiod'. It can also be 'timestep' but might generate errors.
frequency='hourly', # If 'daily', accim will aggregate the rows in days. It can be 'hourly', 'daily', 'monthly' and 'runperiod'. It can also be 'timestep' but might generate errors.
frequency_agg_func='sum', #this makes the sum or average when aggregating in days, months or runperiod; since the original CSV frequency is in hour, it won't make any aeffect
standard_outputs=True,
concatenated_csv_name=concatenated_csvname #Useful when working with large datasets. It saves the output dataset to a CSV file, so you don't need to re-do some work. Afterwards, it can be imported with source_concatenated_csv_filepath argument.
# All other arguments won't have any effect on the output. This is only to store the csv at early stage. Datawrangling will be performed later.
)
Input data frequency in file TestModel[CS_INT EN16798[CA_1[CM_0[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_Aberdeen_Present.csv is hourly, therefore no aggregation will be performed.
Input data frequency in file TestModel[CS_INT EN16798[CA_1[CM_0[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_London_Present.csv is hourly, therefore no aggregation will be performed.
Input data frequency in file TestModel[CS_INT EN16798[CA_1[CM_3[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_Aberdeen_Present.csv is hourly, therefore no aggregation will be performed.
Input data frequency in file TestModel[CS_INT EN16798[CA_1[CM_3[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_London_Present.csv is hourly, therefore no aggregation will be performed.
Input data frequency in file TestModel[CS_INT EN16798[CA_2[CM_0[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_Aberdeen_Present.csv is hourly, therefore no aggregation will be performed.
Input data frequency in file TestModel[CS_INT EN16798[CA_2[CM_0[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_London_Present.csv is hourly, therefore no aggregation will be performed.
Input data frequency in file TestModel[CS_INT EN16798[CA_2[CM_3[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_Aberdeen_Present.csv is hourly, therefore no aggregation will be performed.
Input data frequency in file TestModel[CS_INT EN16798[CA_2[CM_3[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_London_Present.csv is hourly, therefore no aggregation will be performed.
Input data frequency in file TestModel[CS_INT EN16798[CA_3[CM_0[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_Aberdeen_Present.csv is hourly, therefore no aggregation will be performed.
Input data frequency in file TestModel[CS_INT EN16798[CA_3[CM_0[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_London_Present.csv is hourly, therefore no aggregation will be performed.
Input data frequency in file TestModel[CS_INT EN16798[CA_3[CM_3[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_Aberdeen_Present.csv is hourly, therefore no aggregation will be performed.
Input data frequency in file TestModel[CS_INT EN16798[CA_3[CM_3[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_London_Present.csv is hourly, therefore no aggregation will be performed.
We just generated a CSV, whose name begins with ‘notebook example’, specifies the input data and ends with ‘CSVconcatenated’. If there is some row with NaN, it will be generated another CSV reporting this, but ending with ‘Rows_with_NaNs’. We should be able to see it below:
[10]:
import os
os.listdir()
[10]:
['.ipynb_checkpoints',
'notebook_example[srcfreq-hourly[freq-hourly[frequency_agg_func-sum[standard_outputs-True[CSVconcatenated.csv',
'TestModel[CS_INT EN16798[CA_1[CM_0[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X.idf',
'TestModel[CS_INT EN16798[CA_1[CM_0[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_Aberdeen_Present.csv',
'TestModel[CS_INT EN16798[CA_1[CM_0[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_London_Present.csv',
'TestModel[CS_INT EN16798[CA_1[CM_3[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_Aberdeen_Present.csv',
'TestModel[CS_INT EN16798[CA_1[CM_3[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_London_Present.csv',
'TestModel[CS_INT EN16798[CA_2[CM_0[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_Aberdeen_Present.csv',
'TestModel[CS_INT EN16798[CA_2[CM_0[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_London_Present.csv',
'TestModel[CS_INT EN16798[CA_2[CM_3[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_Aberdeen_Present.csv',
'TestModel[CS_INT EN16798[CA_2[CM_3[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_London_Present.csv',
'TestModel[CS_INT EN16798[CA_3[CM_0[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_Aberdeen_Present.csv',
'TestModel[CS_INT EN16798[CA_3[CM_0[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_London_Present.csv',
'TestModel[CS_INT EN16798[CA_3[CM_3[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_Aberdeen_Present.csv',
'TestModel[CS_INT EN16798[CA_3[CM_3[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X[United-Kingdom_London_Present.csv',
'using_Table.ipynb',
'__init__.py']
Now, let’s continue working with the CSVconcatenated we have generated:
[11]:
dataset_hourly_indirect = Table(
source_concatenated_csv_filepath='notebook_example[srcfreq-hourly[freq-hourly[frequency_agg_func-sum[standard_outputs-True[CSVconcatenated.csv',
# source_frequency='hourly', # The new source frequency is the previous already computed frequency, since we have already aggregated rows based on the previous frequency. Therefore, there is no need to specify this argument.
# 3 arguments below have been previously specified, and in fact, are stored at the concatenated CSV filename. So you don't need to specify these again.
# frequency='hourly',
# frequency_agg_func='sum',
# standard_outputs=True,
level=['building'],
level_agg_func=['sum', 'mean'],
level_excluded_zones=[],
split_epw_names=True, #to split EPW names based on the format Country_City_RCPscenario-YEar
idf_path='TestModel[CS_INT EN16798[CA_1[CM_0[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X.idf', # Any of the simulated IDFs, considering all of these are the same building and therefore have the same zones. Used to scan the zones and identify them in the CSVs.
)
No zones have been excluded from level computations.
All CSVs are for present scenario.
[12]:
dataset_hourly_indirect.df.shape
[12]:
(105120, 111)
You can see we have obtained the same full dataset. Now, let’s delete the concatenated CSV file to save some space.
[13]:
new_files = [i for i in os.listdir() if i not in previous_files]
for i in new_files:
os.remove(i)
2. Filtering results
We have used any of the 2 methods to obtain the full dataset of simulation results.
At this point, we should have decided what table or graph we intend to make, and therefore we should know what data we are going to show in it. In this case, we want to make a figure to plot the indoor operative temperature and adaptive heating and cooling setpoints on the y main axis (left spine), and on the secondary y axis, 2 different spines, one of them to show the heating and cooling energy demand, and the other one the air changes, therefore, we will need to filter these columns. Let’s take a look first at the full dataframe:
[14]:
print(*dataset_hourly.df.columns, sep='\n')
Source
Model
ComfStand
CAT
ComfMod
HVACmode
VentCtrl
VSToffset
MinOToffset
MaxWindSpeed
ASTtol
NameSuffix
EPW
Count
EPW_Country_name
EPW_City_or_subcountry
EPW_Scenario-Year
EPW_Scenario
EPW_Year
Date/time
Month/day
Month
Day
Hour
Minute
Second
Site Outdoor Air Drybulb Temperature (°C)
Site Outdoor Air Relative Humidity (%)
Site Wind Speed (m/s)
Comfort Temperature (°C)
Adaptive Cooling Setpoint Temperature (°C)
Adaptive Heating Setpoint Temperature (°C)
Adaptive Cooling Setpoint Temperature_No Tolerance (°C)
Adaptive Heating Setpoint Temperature_No Tolerance (°C)
Ventilation Setpoint Temperature (°C)
Minimum Outdoor Temperature for ventilation (°C)
EMS:COMFORTABLE HOURS_NO APPLICABILITY_BLOCK1_ZONE2 [H](HOURLY)
EMS:COMFORTABLE HOURS_NO APPLICABILITY_BLOCK1_ZONE1 [H](HOURLY)
EMS:COMFORTABLE HOURS_APPLICABILITY_BLOCK1_ZONE2 [H](HOURLY)
EMS:COMFORTABLE HOURS_APPLICABILITY_BLOCK1_ZONE1 [H](HOURLY)
EMS:DISCOMFORTABLE APPLICABLE HOT HOURS_BLOCK1_ZONE2 [H](HOURLY)
EMS:DISCOMFORTABLE APPLICABLE HOT HOURS_BLOCK1_ZONE1 [H](HOURLY)
EMS:DISCOMFORTABLE APPLICABLE COLD HOURS_BLOCK1_ZONE2 [H](HOURLY)
EMS:DISCOMFORTABLE APPLICABLE COLD HOURS_BLOCK1_ZONE1 [H](HOURLY)
EMS:DISCOMFORTABLE NON APPLICABLE HOT HOURS_BLOCK1_ZONE2 [H](HOURLY)
EMS:DISCOMFORTABLE NON APPLICABLE HOT HOURS_BLOCK1_ZONE1 [H](HOURLY)
EMS:DISCOMFORTABLE NON APPLICABLE COLD HOURS_BLOCK1_ZONE2 [H](HOURLY)
EMS:DISCOMFORTABLE NON APPLICABLE COLD HOURS_BLOCK1_ZONE1 [H](HOURLY)
EMS:ZONE FLOOR AREA_BLOCK1_ZONE2 [M2](HOURLY)
EMS:ZONE FLOOR AREA_BLOCK1_ZONE1 [M2](HOURLY)
EMS:ZONE AIR VOLUME_BLOCK1_ZONE2 [M3](HOURLY)
EMS:ZONE AIR VOLUME_BLOCK1_ZONE1 [M3](HOURLY)
EMS:VENTILATION HOURS_BLOCK1_ZONE2 [H](HOURLY)
EMS:VENTILATION HOURS_BLOCK1_ZONE1 [H](HOURLY)
Block1:Zone2_Zone Operative Temperature (°C)
Block1:Zone1_Zone Operative Temperature (°C)
Block1:Zone2_AFN Zone Infiltration Volume (m3)
Block1:Zone2_AFN Zone Infiltration Air Change Rate (ach)
Block1:Zone1_AFN Zone Infiltration Volume (m3)
Block1:Zone1_AFN Zone Infiltration Air Change Rate (ach)
Whole Building Facility Total HVAC Electricity Demand Rate (kWh/m2)
Block1:Zone2_ASHRAE 55 Running mean outdoor temperature (°C)
Block1:Zone2_EN16798-1 Running mean outdoor temperature (°C)
Block1:Zone1_ASHRAE 55 Running mean outdoor temperature (°C)
Block1:Zone1_EN16798-1 Running mean outdoor temperature (°C)
Block1:Zone2_Cooling Energy Demand (kWh/m2)
Block1:Zone1_Cooling Energy Demand (kWh/m2)
Block1:Zone2_Heating Energy Demand (kWh/m2)
Block1:Zone1_Heating Energy Demand (kWh/m2)
Block1:Zone2_Cooling Energy Consumption (kWh/m2)
Block1:Zone2_Heating Energy Consumption (kWh/m2)
Block1:Zone1_Cooling Energy Consumption (kWh/m2)
Block1:Zone1_Heating Energy Consumption (kWh/m2)
Block1:Zone2_Total Energy Demand (kWh/m2) (summed)
Block1:Zone1_Total Energy Demand (kWh/m2) (summed)
Block1:Zone2_Total Energy Consumption (kWh/m2) (summed)
Block1:Zone1_Total Energy Consumption (kWh/m2) (summed)
Building_Total_Zone Air Volume (m3) (summed)
Building_Total_Zone Floor Area (m2) (summed)
Building_Total_Zone Operative Temperature (°C) (summed)
Building_Total_Zone Operative Temperature (°C) (mean)
Building_Total_Comfortable Hours_No Applicability (h) (summed)
Building_Total_Comfortable Hours_No Applicability (h) (mean)
Building_Total_Comfortable Hours_Applicability (h) (summed)
Building_Total_Comfortable Hours_Applicability (h) (mean)
Building_Total_Discomfortable Applicable Hot Hours (h) (summed)
Building_Total_Discomfortable Applicable Hot Hours (h) (mean)
Building_Total_Discomfortable Applicable Cold Hours (h) (summed)
Building_Total_Discomfortable Applicable Cold Hours (h) (mean)
Building_Total_Discomfortable Non Applicable Hot Hours (h) (summed)
Building_Total_Discomfortable Non Applicable Hot Hours (h) (mean)
Building_Total_Discomfortable Non Applicable Cold Hours (h) (summed)
Building_Total_Discomfortable Non Applicable Cold Hours (h) (mean)
Building_Total_Ventilation Hours (h) (summed)
Building_Total_Ventilation Hours (h) (mean)
Building_Total_AFN Zone Infiltration Volume (m3) (summed)
Building_Total_AFN Zone Infiltration Volume (m3) (mean)
Building_Total_AFN Zone Infiltration Air Change Rate (ach) (summed)
Building_Total_AFN Zone Infiltration Air Change Rate (ach) (mean)
Building_Total_Cooling Energy Demand (kWh/m2) (summed)
Building_Total_Cooling Energy Demand (kWh/m2) (mean)
Building_Total_Heating Energy Demand (kWh/m2) (summed)
Building_Total_Heating Energy Demand (kWh/m2) (mean)
Building_Total_Cooling Energy Consumption (kWh/m2) (summed)
Building_Total_Cooling Energy Consumption (kWh/m2) (mean)
Building_Total_Heating Energy Consumption (kWh/m2) (summed)
Building_Total_Heating Energy Consumption (kWh/m2) (mean)
Building_Total_Total Energy Demand (kWh/m2) (summed)
Building_Total_Total Energy Demand (kWh/m2) (mean)
Building_Total_Total Energy Consumption (kWh/m2) (summed)
Building_Total_Total Energy Consumption (kWh/m2) (mean)
Now, let’s extract the data we are really interested in. For this, we can use the method called format_table():
[15]:
dataset_hourly.format_table(
type_of_table='custom', # Used to choose some predefined tables. It can be 'energy demand', 'comfort hours', 'temperature', 'all' or 'custom'
custom_cols=[ #if type_of_table is 'custom', custom_cols is used to filter the desired columns to keep
'Adaptive Cooling Setpoint Temperature_No Tolerance (°C)',
'Adaptive Heating Setpoint Temperature_No Tolerance (°C)',
'Building_Total_Zone Operative Temperature (°C) (mean)',
'BLOCK1:ZONE2_EN16798-1 Running mean outdoor temperature (°C)',
'Building_Total_Cooling Energy Demand (kWh/m2) (summed)',
'Building_Total_Heating Energy Demand (kWh/m2) (summed)',
'Building_Total_AFN Zone Infiltration Air Change Rate (ach) (summed)'
]
)
So, we have already filtered the columns we wanted. Let’s look at the result:
[16]:
dataset_hourly.df
[16]:
| Date/time | Model | ComfStand | CAT | ComfMod | HVACmode | VentCtrl | VSToffset | MinOToffset | MaxWindSpeed | ... | EPW_Scenario-Year | EPW_Scenario | EPW_Year | Adaptive Cooling Setpoint Temperature_No Tolerance (°C) | Adaptive Heating Setpoint Temperature_No Tolerance (°C) | Building_Total_Zone Operative Temperature (°C) (mean) | Block1:Zone2_EN16798-1 Running mean outdoor temperature (°C) | Building_Total_Cooling Energy Demand (kWh/m2) (summed) | Building_Total_Heating Energy Demand (kWh/m2) (summed) | Building_Total_AFN Zone Infiltration Air Change Rate (ach) (summed) | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 01/01 01:00:00 | TestModel | CS_INT EN16798 | CA_1 | CM_0 | HM_2 | VC_0 | VO_0 | MT_50 | MW_50 | ... | Present | Present | Present | 25.0 | 21.0 | 21.075965 | -1.071071 | 0.0 | 0.036738 | 0.217716 |
| 1 | 01/01 02:00:00 | TestModel | CS_INT EN16798 | CA_1 | CM_0 | HM_2 | VC_0 | VO_0 | MT_50 | MW_50 | ... | Present | Present | Present | 25.0 | 21.0 | 21.060730 | -1.071071 | 0.0 | 0.040240 | 0.229646 |
| 2 | 01/01 03:00:00 | TestModel | CS_INT EN16798 | CA_1 | CM_0 | HM_2 | VC_0 | VO_0 | MT_50 | MW_50 | ... | Present | Present | Present | 25.0 | 21.0 | 21.061641 | -1.071071 | 0.0 | 0.042701 | 0.238609 |
| 3 | 01/01 04:00:00 | TestModel | CS_INT EN16798 | CA_1 | CM_0 | HM_2 | VC_0 | VO_0 | MT_50 | MW_50 | ... | Present | Present | Present | 25.0 | 21.0 | 21.068896 | -1.071071 | 0.0 | 0.044282 | 0.242288 |
| 4 | 01/01 05:00:00 | TestModel | CS_INT EN16798 | CA_1 | CM_0 | HM_2 | VC_0 | VO_0 | MT_50 | MW_50 | ... | Present | Present | Present | 25.0 | 21.0 | 21.078253 | -1.071071 | 0.0 | 0.045109 | 0.243261 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 105115 | 12/31 20:00:00 | TestModel | CS_INT EN16798 | CA_3 | CM_3 | HM_2 | VC_0 | VO_0 | MT_50 | MW_50 | ... | Present | Present | Present | 26.1 | 17.1 | 17.171267 | 7.543148 | 0.0 | 0.011349 | 0.180364 |
| 105116 | 12/31 21:00:00 | TestModel | CS_INT EN16798 | CA_3 | CM_3 | HM_2 | VC_0 | VO_0 | MT_50 | MW_50 | ... | Present | Present | Present | 26.1 | 17.1 | 17.176058 | 7.543148 | 0.0 | 0.011955 | 0.175023 |
| 105117 | 12/31 22:00:00 | TestModel | CS_INT EN16798 | CA_3 | CM_3 | HM_2 | VC_0 | VO_0 | MT_50 | MW_50 | ... | Present | Present | Present | 26.1 | 17.1 | 17.178160 | 7.543148 | 0.0 | 0.012974 | 0.191868 |
| 105118 | 12/31 23:00:00 | TestModel | CS_INT EN16798 | CA_3 | CM_3 | HM_2 | VC_0 | VO_0 | MT_50 | MW_50 | ... | Present | Present | Present | 26.1 | 17.1 | 17.176237 | 7.543148 | 0.0 | 0.015072 | 0.255266 |
| 105119 | 12/31 24:00:00 | TestModel | CS_INT EN16798 | CA_3 | CM_3 | HM_2 | VC_0 | VO_0 | MT_50 | MW_50 | ... | Present | Present | Present | 26.1 | 17.1 | 17.170725 | 7.543148 | 0.0 | 0.017182 | 0.281407 |
105120 rows × 29 columns
As you can see, the number of columns have been reduced to 29, which are 22 columns for the index and categorical data, and the 7 columns we filtered.
3. Making graphs
At this point, you might be confused about what can you analyse and plot. The way to identify the IDFs individually is combining or gathering the categorical variables that make them different. In this case, for the IDFs, these are ComfMod and HVACmode (as we requested in the addAccis instance). In case of the EPW files, the columns related to these are:
[17]:
[i for i in dataset_hourly.df if 'EPW' in i]
[17]:
['EPW',
'EPW_Country_name',
'EPW_City_or_subcountry',
'EPW_Scenario-Year',
'EPW_Scenario',
'EPW_Year']
Therefore, EPW_City_or_subcountry should be enough to identify them, since it’s the only categorical variables with multiple values (i.e. Country is always “United-Kingdom”, and EPW_Scenario-Year, EPW_Scenario and EPW_Year are “Present” in all cases).
To get a clearer view, you can use the method gather_vars_query, which will provide a list of the categorical variables extracted from the csv filename that change, and therefore, can be used in the analysis, and the values these contain. Let’s try it:
[18]:
dataset_hourly.gather_vars_query()
The categorical columns which have different values and those values are:
CAT: ['CA_1', 'CA_2', 'CA_3']
ComfMod: ['CM_0', 'CM_3']
EPW_City_or_subcountry: ['Aberdeen', 'London']
Month: ['01', '02', '03', '04', '05', '06', '07', '08', '09', '10', '11', '12']
Day: ['01', '02', '03', '04', '05', '06', '07', '08', '09', '10', '11', '12', '13', '14', '15', '16', '17', '18', '19', '20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31']
Hour: ['00', '01', '02', '03', '04', '05', '06', '07', '08', '09', '10', '11', '12', '13', '14', '15', '16', '17', '18', '19', '20', '21', '22', '23']
3.1 Scatter plot:
Therefore, based on the output of gather_vars_query(), some possible interesing graph would be a seaborn.FacetGrid -alike plot (or graph with subplots), which would have the combination of arguments CAT and ComfMod in the columns, and the values for the cities in the rows. Let’s plot it:
[19]:
dataset_hourly.scatter_plot(
vars_to_gather_rows=['ComfMod', 'CAT'], # variables to gather in rows of subplots
vars_to_gather_cols=['EPW_City_or_subcountry'],# variables to gather in columns of subplots
detailed_rows=['CM_0[CA_3', 'CM_3[CA_3'], #we only want to see those combinations
data_on_x_axis='BLOCK1:ZONE2_EN16798-1 Running mean outdoor temperature (°C)', #column name (string) for the data on x axis
data_on_y_main_axis=[ # similarly to above, a list including the name of the secondary y-axis and the column names you want to plot in it
[
'Energy (kWh/m2)',
[
'Building_Total_Cooling Energy Demand (kWh/m2) (summed)',
'Building_Total_Heating Energy Demand (kWh/m2) (summed)',
]
],
],
data_on_y_sec_axis=[ #list which includes the name of the axis on the first place, and then in the second place, a list which includes the column names you want to plot
[
'Air renovation (ach)',
[
'Building_Total_AFN Zone Infiltration Air Change Rate (ach) (summed)'
]
],
[
'Operative Temperature (°C)',
[
'Adaptive Cooling Setpoint Temperature_No Tolerance (°C)',
'Adaptive Heating Setpoint Temperature_No Tolerance (°C)',
'Building_Total_Zone Operative Temperature (°C) (mean)',
]
],
],
colorlist_y_main_axis=[
[
'Energy (kWh/m2)',
[
'cyan',
'orange',
]
],
],
colorlist_y_sec_axis=[
[
'Air renovation (ach)',
[
'yellow'
]
],
[
'Operative Temperature (°C)',
[
'b',
'r',
'g',
]
],
],
supxlabel='Running Mean Outdoor Temperature (°C)', # data label on x axis
figname=f'WIP_scatterplot_RMOT',
figsize=6,
ratio_height_to_width=0.33,
confirm_graph=True
)
The number of rows and the list of these is going to be:
No. of rows = 2
List of rows:
CM_0[CA_3
CM_3[CA_3
Do you want to rename the rows? [y/n]: y
Please enter the new name for CM_0[CA_3: Static setpoints
Please enter the new name for CM_3[CA_3: Adaptive setpoints
The renamed rows are going to be:
Static setpoints
Adaptive setpoints
The number of columns and the list of these is going to be:
No. of columns = 2
List of columns:
Aberdeen
London
Column names will be the subplot titles. Do you want to rename them? [y/n]: n
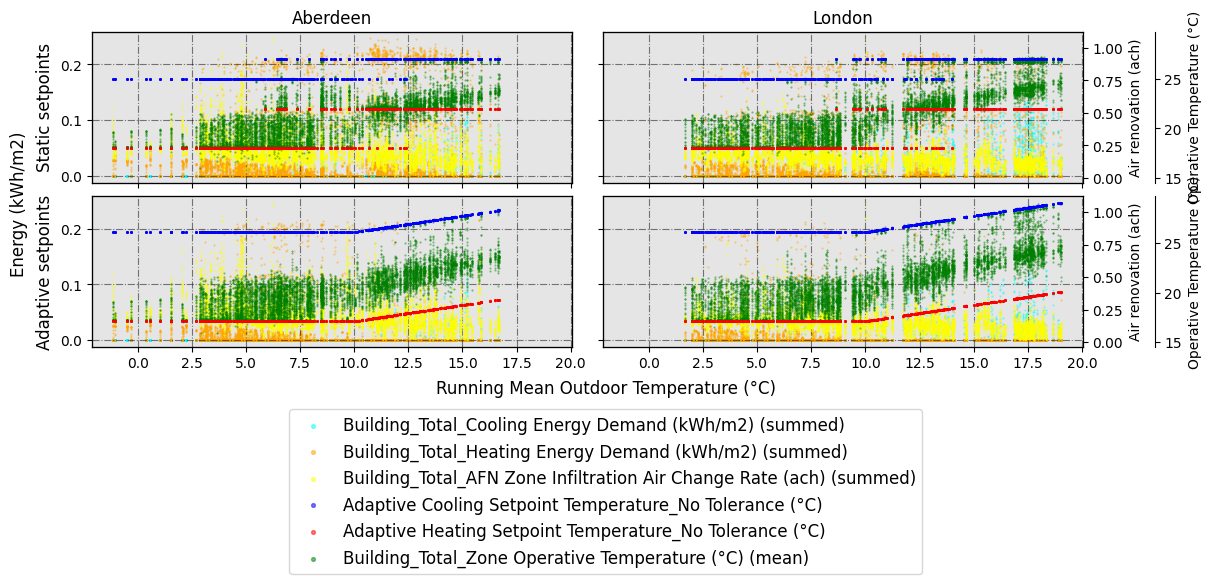
3.2 Adaptive vs Static data scatter plot:
A very specific type of scatter plot can be done to show the relationship between data related to adaptive and static setpoint temperatures. In this case, you would need to use the scatter_plot_with_baseline() function.
[20]:
dataset_hourly.scatter_plot_with_baseline(
vars_to_gather_rows=['EPW_City_or_subcountry'], #you can enter multiple variables, for example: ['EPW_City_or_subcountry', 'EPW_Scenario-Year']
vars_to_gather_cols=['ComfMod', 'CAT'], #you can enter multiple variables
data_on_y_axis_baseline_plot=[ # in this case, you only need to specify a list which includes the data columns you want to plot
'Building_Total_Cooling Energy Demand (kWh/m2) (summed)',
'Building_Total_Heating Energy Demand (kWh/m2) (summed)',
],
baseline='CM_0[CA_1', # the baseline needs to be in vars_to_gather_cols, and it's going to be shown on x axis. Given the variables we have simulated, you can choose between 'CM_0[CA_1', 'CM_0[CA_2', 'CM_0[CA_3', 'CM_3[CA_1', 'CM_3[CA_2' and 'CM_3[CA_3'
colorlist_baseline_plot_data=[
'b',
'r',
],
supxlabel='Static Energy Demand (kWh/m2)',
supylabel='Adaptive Energy Demand (kWh/m2)',
figname='WIP_scatterplot_adap_vs_stat',
figsize=3,
confirm_graph=True
)
The number of rows and the list of these is going to be:
No. of rows = 2
List of rows:
Aberdeen
London
Do you want to rename the rows? [y/n]: n
The number of columns and the list of these is going to be:
No. of columns = 5
List of columns:
CM_0[CA_2
CM_0[CA_3
CM_3[CA_1
CM_3[CA_2
CM_3[CA_3
Column names will be the subplot titles. Do you want to rename them? [y/n]: n
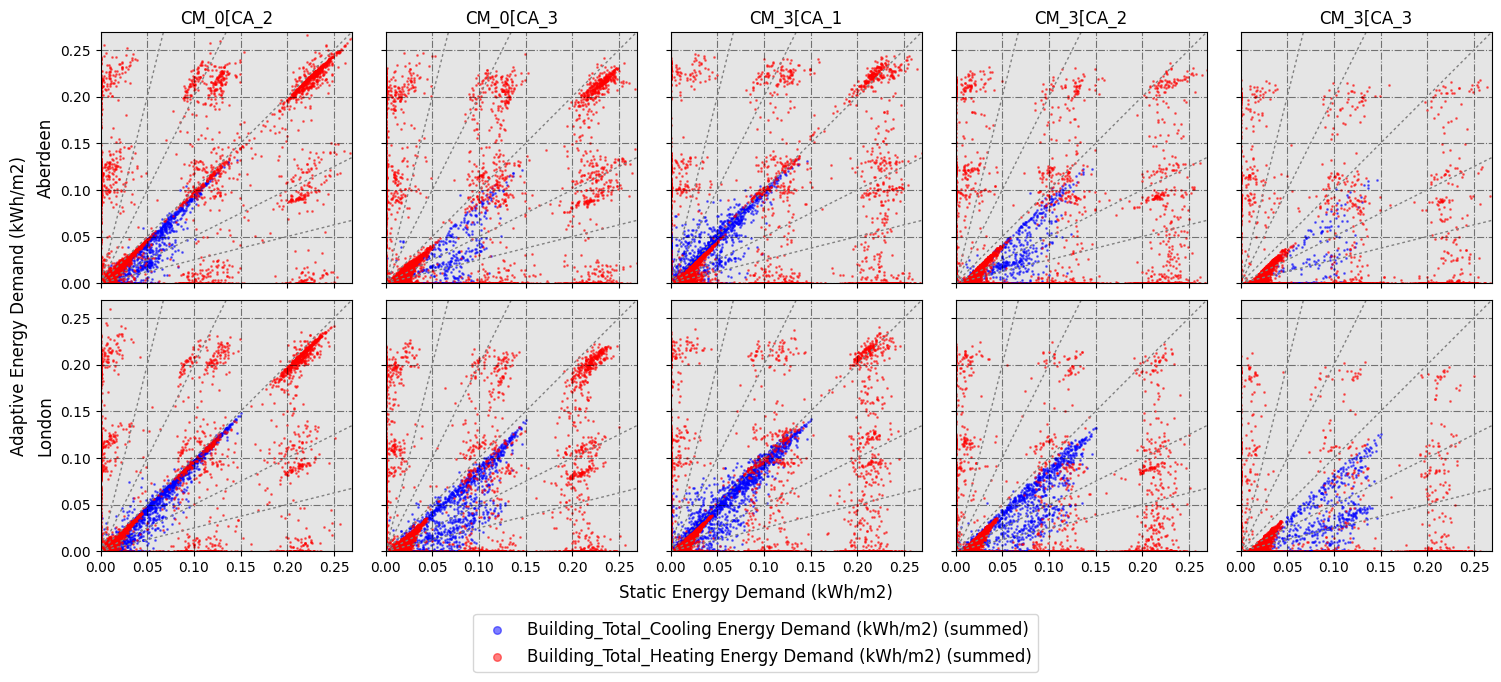
Now, let’s delete all the images we have created to save some space:
[21]:
new_files = [i for i in os.listdir() if i not in previous_files]
for i in new_files:
os.remove(i)
4. Making tables
Now, let’s make some tables comparing results. For example, let’s make a table to show monthly values of heating and cooling energy demand. First, let’s generate the dataset with monthly frequency and let’s filter the columns to keep heating and cooling demand at building level.
[22]:
from accim.data.postprocessing.main import Table
dataset_monthly = Table(
#datasets=list Since we are not specifying any list, it will use all available CSVs in the folder
source_frequency='hourly',
frequency='monthly',
frequency_agg_func='sum', #this makes the sum or average when aggregating in days, months or runperiod; since the original CSV frequency is in hour, it won't make any aeffect
standard_outputs=True,
level=['building'],
level_agg_func=['sum'],
level_excluded_zones=[],
split_epw_names=True, #to split EPW names based on the format Country_City_RCPscenario-YEar
idf_path='TestModel[CS_INT EN16798[CA_1[CM_0[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X.idf', # Any of the simulated IDFs, considering all of these are the same building and therefore have the same zones. Used to scan the zones and identify them in the CSVs.
)
dataset_monthly.format_table(
type_of_table='custom',
custom_cols=[
'Building_Total_Cooling Energy Demand (kWh/m2) (summed)',
'Building_Total_Heating Energy Demand (kWh/m2) (summed)',
]
)
No zones have been excluded from level computations.
All CSVs are for present scenario.
Now, let’s make the table we are looking for. You can choose ‘multiindex’, ‘unstack’ or ‘pivot’ as a reshaping method (remember that we are actually working with Pandas Dataframes). Let’s go with unstack, and we are going to compare the baseline shown below with all gathered variables
[23]:
dataset_monthly.wrangled_table(
reshaping='unstack', #can be 'unstack' or 'pivot'
vars_to_gather=['ComfMod', 'CAT'],
vars_to_keep=['EPW_City_or_subcountry', 'Month'],
baseline='CM_0[CA_1',
comparison_mode=['baseline compared to others'], #can be 'baseline compared to others' or 'others compared to baseline'
comparison_cols=['relative', 'absolute'] #'relative' to show the difference as a percentage, 'absolute' to show the difference by subtracting
)
[24]:
dataset_monthly.wrangled_df_unstacked
[24]:
| Building_Total_Cooling Energy Demand (kWh/m2) (summed) | ... | Building_Total_Heating Energy Demand (kWh/m2) (summed) | ||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CM_0[CA_1 | CM_3[CA_1 | CM_0[CA_2 | CM_3[CA_2 | CM_0[CA_3 | CM_3[CA_3 | 1-(CM_0[CA_1/CM_3[CA_1) | CM_3[CA_1 - CM_0[CA_1 | 1-(CM_0[CA_1/CM_0[CA_2) | CM_0[CA_2 - CM_0[CA_1 | ... | 1-(CM_0[CA_1/CM_3[CA_1) | CM_3[CA_1 - CM_0[CA_1 | 1-(CM_0[CA_1/CM_0[CA_2) | CM_0[CA_2 - CM_0[CA_1 | 1-(CM_0[CA_1/CM_3[CA_2) | CM_3[CA_2 - CM_0[CA_1 | 1-(CM_0[CA_1/CM_0[CA_3) | CM_0[CA_3 - CM_0[CA_1 | 1-(CM_0[CA_1/CM_3[CA_3) | CM_3[CA_3 - CM_0[CA_1 | ||
| Month | EPW_City_or_subcountry | |||||||||||||||||||||
| 01 | Aberdeen | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | NaN | 0.00 | NaN | 0.00 | ... | -0.26 | -3.05 | -0.16 | -2.11 | -0.67 | -6.02 | -0.65 | -5.90 | -1.11 | -7.88 |
| London | 0.12 | 0.00 | 0.04 | 0.00 | 0.00 | 0.00 | -inf | -0.12 | -2.14 | -0.08 | ... | -0.08 | -1.35 | -0.12 | -1.96 | -0.54 | -6.20 | -0.58 | -6.50 | -1.16 | -9.53 | |
| 02 | Aberdeen | 0.29 | 0.26 | 0.14 | 0.00 | 0.00 | 0.00 | -0.14 | -0.04 | -1.08 | -0.15 | ... | -0.12 | -2.05 | -0.09 | -1.52 | -0.37 | -5.24 | -0.39 | -5.43 | -1.01 | -9.65 |
| London | 0.43 | 0.09 | 0.07 | 0.00 | 0.00 | 0.00 | -3.98 | -0.34 | -5.36 | -0.36 | ... | 0.01 | 0.17 | -0.04 | -0.78 | -0.39 | -5.15 | -0.44 | -5.59 | -1.21 | -10.06 | |
| 03 | Aberdeen | 1.39 | 1.06 | 0.71 | 0.26 | 0.26 | 0.06 | -0.32 | -0.33 | -0.97 | -0.69 | ... | -0.02 | -0.41 | -0.03 | -0.72 | -0.23 | -4.67 | -0.26 | -5.14 | -0.80 | -11.02 |
| London | 1.34 | 0.95 | 0.82 | 0.06 | 0.00 | 0.00 | -0.41 | -0.39 | -0.64 | -0.52 | ... | 0.05 | 1.29 | -0.08 | -1.80 | -0.27 | -5.44 | -0.26 | -5.28 | -1.04 | -12.95 | |
| 04 | Aberdeen | 3.38 | 2.72 | 1.92 | 0.79 | 0.32 | 0.00 | -0.24 | -0.66 | -0.76 | -1.45 | ... | 0.04 | 1.18 | 0.02 | 0.62 | -0.12 | -2.87 | -0.12 | -2.72 | -0.56 | -9.36 |
| London | 6.95 | 6.75 | 5.65 | 2.76 | 2.66 | 0.72 | -0.03 | -0.20 | -0.23 | -1.30 | ... | -0.09 | -1.91 | -0.10 | -1.95 | -0.47 | -7.04 | -0.55 | -7.87 | -1.79 | -14.23 | |
| 05 | Aberdeen | 8.78 | 7.24 | 5.67 | 1.67 | 1.42 | 0.09 | -0.21 | -1.54 | -0.55 | -3.11 | ... | -0.36 | -9.43 | 0.15 | 6.35 | -0.69 | -14.40 | 0.19 | 8.35 | -2.12 | -24.07 |
| London | 14.37 | 14.89 | 11.25 | 8.51 | 4.88 | 3.60 | 0.03 | 0.52 | -0.28 | -3.12 | ... | -1.84 | -28.72 | 0.15 | 7.73 | -4.41 | -36.14 | 0.08 | 3.91 | -16.23 | -41.76 | |
| 06 | Aberdeen | 12.16 | 11.19 | 8.94 | 4.83 | 2.89 | 1.35 | -0.09 | -0.98 | -0.36 | -3.22 | ... | -0.95 | -20.62 | 0.08 | 3.45 | -1.32 | -24.09 | -0.00 | -0.14 | -4.55 | -34.76 |
| London | 16.10 | 16.39 | 14.03 | 10.63 | 9.05 | 5.27 | 0.02 | 0.29 | -0.15 | -2.07 | ... | -2.43 | -30.47 | 0.04 | 1.86 | -7.01 | -37.66 | -0.29 | -9.79 | -33.04 | -41.77 | |
| 07 | Aberdeen | 12.15 | 12.88 | 9.30 | 5.85 | 4.02 | 1.65 | 0.06 | 0.73 | -0.31 | -2.85 | ... | -2.70 | -36.28 | 0.12 | 6.50 | -9.81 | -45.11 | -0.08 | -3.64 | -245.24 | -49.51 |
| London | 25.21 | 18.93 | 22.81 | 10.30 | 15.55 | 4.38 | -0.33 | -6.28 | -0.11 | -2.41 | ... | -0.31 | -2.70 | 0.22 | 3.16 | -3.47 | -8.85 | 0.23 | 3.32 | -51.57 | -11.18 | |
| 08 | Aberdeen | 11.45 | 11.50 | 8.82 | 4.58 | 4.13 | 2.37 | 0.00 | 0.04 | -0.30 | -2.63 | ... | -2.32 | -31.05 | 0.12 | 5.91 | -7.08 | -38.92 | -0.10 | -3.91 | -40.97 | -43.37 |
| London | 22.48 | 16.96 | 19.97 | 10.88 | 13.45 | 5.21 | -0.33 | -5.53 | -0.13 | -2.51 | ... | -0.73 | -6.28 | 0.17 | 3.10 | -5.00 | -12.40 | -0.06 | -0.83 | -46.92 | -14.57 | |
| 09 | Aberdeen | 3.24 | 4.74 | 1.39 | 0.77 | 0.29 | 0.17 | 0.32 | 1.50 | -1.34 | -1.86 | ... | -2.74 | -40.09 | 0.09 | 5.11 | -4.90 | -45.43 | -0.18 | -8.19 | -12.52 | -50.66 |
| London | 10.22 | 10.32 | 8.71 | 5.35 | 4.03 | 1.56 | 0.01 | 0.09 | -0.17 | -1.52 | ... | -2.71 | -31.33 | -0.03 | -1.20 | -8.28 | -38.27 | -0.36 | -11.29 | -38.49 | -41.80 | |
| 10 | Aberdeen | 0.27 | 0.38 | 0.18 | 0.00 | 0.24 | 0.00 | 0.29 | 0.11 | -0.55 | -0.10 | ... | -0.27 | -6.41 | -0.25 | -5.88 | -0.96 | -14.61 | -1.16 | -15.99 | -2.84 | -22.01 |
| London | 3.85 | 4.53 | 3.66 | 1.18 | 3.32 | 0.35 | 0.15 | 0.68 | -0.05 | -0.19 | ... | -0.77 | -11.56 | -0.42 | -7.85 | -2.65 | -19.23 | -4.72 | -21.86 | -12.53 | -24.53 | |
| 11 | Aberdeen | 0.05 | 0.04 | 0.07 | 0.00 | 0.00 | 0.00 | -0.11 | -0.00 | 0.28 | 0.02 | ... | -0.05 | -0.82 | -0.16 | -2.45 | -0.55 | -6.37 | -0.57 | -6.53 | -1.48 | -10.69 |
| London | 0.40 | 0.05 | 0.10 | 0.00 | 0.00 | 0.00 | -7.45 | -0.35 | -2.81 | -0.29 | ... | -0.01 | -0.15 | -0.08 | -1.62 | -0.61 | -8.43 | -0.61 | -8.42 | -2.35 | -15.54 | |
| 12 | Aberdeen | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | NaN | 0.00 | NaN | 0.00 | ... | -0.23 | -2.81 | -0.17 | -2.26 | -0.69 | -6.27 | -0.75 | -6.55 | -1.51 | -9.19 |
| London | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | NaN | 0.00 | NaN | 0.00 | ... | -0.10 | -1.46 | -0.20 | -2.79 | -0.75 | -7.03 | -0.71 | -6.86 | -1.75 | -10.48 | |
24 rows × 32 columns
Let’s make a different dataset to work with runperiod frequency.
[25]:
from accim.data.postprocessing.main import Table
dataset_runperiod = Table(
#datasets=list Since we are not specifying any list, it will use all available CSVs in the folder
source_frequency='hourly',
frequency='runperiod',
frequency_agg_func='sum', #this makes the sum or average when aggregating in days, months or runperiod; since the original CSV frequency is in hour, it won't make any aeffect
standard_outputs=True,
level=['building'],
level_agg_func=['sum'],
level_excluded_zones=[],
split_epw_names=True, #to split EPW names based on the format Country_City_RCPscenario-YEar
idf_path='TestModel[CS_INT EN16798[CA_1[CM_0[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X.idf', # Any of the simulated IDFs, considering all of these are the same building and therefore have the same zones. Used to scan the zones and identify them in the CSVs.
)
dataset_runperiod.format_table(
type_of_table='custom',
custom_cols=[
'Building_Total_Cooling Energy Demand (kWh/m2) (summed)',
'Building_Total_Heating Energy Demand (kWh/m2) (summed)',
]
)
No zones have been excluded from level computations.
All CSVs are for present scenario.
In this case, we are going to use the ‘pivot’ reshaping option:
[26]:
dataset_runperiod.wrangled_table(
reshaping='pivot',
vars_to_gather=['ComfMod', 'CAT'],
baseline='CM_0[CA_1',
comparison_mode=['baseline compared to others'],
comparison_cols=['relative', 'absolute']
)
C:\users\sanga\appdata\local\programs\python\python39\lib\site-packages\accim\data\postprocessing\main.py:1684: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.df['col_to_pivot'] = 'temp'
C:\users\sanga\appdata\local\programs\python\python39\lib\site-packages\accim\data\postprocessing\main.py:1697: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.df['col_to_pivot'] = wrangled_df_pivoted['col_to_pivot']
C:\users\sanga\appdata\local\programs\python\python39\lib\site-packages\accim\data\postprocessing\main.py:1777: FutureWarning: The provided callable <function sum at 0x000001B0A2D75E50> is currently using DataFrameGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
wrangled_df_pivoted = wrangled_df_pivoted.pivot_table(
[27]:
dataset_runperiod.wrangled_df_pivoted
[27]:
| col_to_pivot | CM_0[CA_1 | CM_0[CA_2 | CM_0[CA_3 | CM_3[CA_1 | CM_3[CA_2 | CM_3[CA_3 | 1-(CM_0[CA_1/CM_3[CA_2) | CM_3[CA_2 - CM_0[CA_1 | 1-(CM_0[CA_1/CM_0[CA_2) | CM_0[CA_2 - CM_0[CA_1 | 1-(CM_0[CA_1/CM_3[CA_1) | CM_3[CA_1 - CM_0[CA_1 | 1-(CM_0[CA_1/CM_0[CA_3) | CM_0[CA_3 - CM_0[CA_1 | 1-(CM_0[CA_1/CM_3[CA_3) | CM_3[CA_3 - CM_0[CA_1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Building_Total_Cooling Energy Demand (kWh/m2) (summed) | 154.66 | 124.24 | 66.51 | 141.86 | 68.41 | 26.77 | -1.26 | -86.24 | -0.24 | -30.42 | -0.09 | -12.80 | -1.33 | -88.14 | -4.78 | -127.89 |
| Building_Total_Heating Energy Demand (kWh/m2) (summed) | 680.07 | 688.99 | 547.22 | 413.73 | 274.22 | 149.52 | -1.48 | -405.85 | 0.01 | 8.92 | -0.64 | -266.33 | -0.24 | -132.84 | -3.55 | -530.55 |
Again, please remember we are working with Pandas Dataframe objects. That means we can modify the df we have generated. For instance, we can simplify it by removing all rows except those with ‘CA_3’ in the Category column, as shown below.
[28]:
dataset_runperiod.df = dataset_runperiod.df[
dataset_runperiod.df['CAT'].isin(['CA_3'])
]
[29]:
dataset_runperiod.df
[29]:
| Model | ComfStand | CAT | ComfMod | HVACmode | VentCtrl | VSToffset | MinOToffset | MaxWindSpeed | ASTtol | NameSuffix | EPW | Source | EPW_Country_name | EPW_City_or_subcountry | EPW_Scenario-Year | EPW_Scenario | EPW_Year | Building_Total_Cooling Energy Demand (kWh/m2) (summed) | Building_Total_Heating Energy Demand (kWh/m2) (summed) | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 8 | TestModel | CS_INT EN16798 | CA_3 | CM_0 | HM_2 | VC_0 | VO_0 | MT_50 | MW_50 | AT_0.1 | NS_X | United-Kingdom_Aberdeen_Present | TestModel[CS_INT EN16798[CA_3[CM_0[HM_2[VC_0[V... | United-Kingdom | Aberdeen | Present | Present | Present | 13.574438 | 318.977783 |
| 9 | TestModel | CS_INT EN16798 | CA_3 | CM_0 | HM_2 | VC_0 | VO_0 | MT_50 | MW_50 | AT_0.1 | NS_X | United-Kingdom_London_Present | TestModel[CS_INT EN16798[CA_3[CM_0[HM_2[VC_0[V... | United-Kingdom | London | Present | Present | Present | 52.938830 | 228.246073 |
| 10 | TestModel | CS_INT EN16798 | CA_3 | CM_3 | HM_2 | VC_0 | VO_0 | MT_50 | MW_50 | AT_0.1 | NS_X | United-Kingdom_Aberdeen_Present | TestModel[CS_INT EN16798[CA_3[CM_3[HM_2[VC_0[V... | United-Kingdom | Aberdeen | Present | Present | Present | 5.687532 | 92.602457 |
| 11 | TestModel | CS_INT EN16798 | CA_3 | CM_3 | HM_2 | VC_0 | VO_0 | MT_50 | MW_50 | AT_0.1 | NS_X | United-Kingdom_London_Present | TestModel[CS_INT EN16798[CA_3[CM_3[HM_2[VC_0[V... | United-Kingdom | London | Present | Present | Present | 21.084511 | 56.917599 |
And now we could make a similar pivoted table as above, but simplified to show only CA_3:
[30]:
dataset_runperiod.wrangled_table(
reshaping='pivot',
vars_to_gather=['ComfMod'],
baseline='CM_0',
comparison_mode=['baseline compared to others'],
comparison_cols=['relative', 'absolute']
)
C:\users\sanga\appdata\local\programs\python\python39\lib\site-packages\accim\data\postprocessing\main.py:1777: FutureWarning: The provided callable <function sum at 0x000001B0A2D75E50> is currently using DataFrameGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
wrangled_df_pivoted = wrangled_df_pivoted.pivot_table(
[31]:
dataset_runperiod.wrangled_df_pivoted
[31]:
| col_to_pivot | CM_0 | CM_3 | 1-(CM_0/CM_3) | CM_3 - CM_0 |
|---|---|---|---|---|
| Building_Total_Cooling Energy Demand (kWh/m2) (summed) | 66.51 | 26.77 | -1.48 | -39.74 |
| Building_Total_Heating Energy Demand (kWh/m2) (summed) | 547.22 | 149.52 | -2.66 | -397.70 |
Another method to achieve this is generating a different Table object, only reading the CSV files with CA_3 in it name:
[32]:
import os
from accim.data.postprocessing.main import Table
dataset = [i for i in os.listdir() if i.endswith('.csv') and 'CA_3' in i]
dataset_runperiod_simplified_1 = Table(
datasets=dataset,
source_frequency='hourly',
frequency='runperiod',
frequency_agg_func='sum',
# this makes the sum or average when aggregating in days, months or runperiod; since the original CSV frequency is in hour, it won't make any aeffect
standard_outputs=True,
level=['building'],
level_agg_func=['sum'],
level_excluded_zones=[],
split_epw_names=True, # to split EPW names based on the format Country_City_RCPscenario-YEar
idf_path='TestModel[CS_INT EN16798[CA_1[CM_0[HM_2[VC_0[VO_0[MT_50[MW_50[AT_0.1[NS_X.idf', # Any of the simulated IDFs, considering all of these are the same building and therefore have the same zones. Used to scan the zones and identify them in the CSVs.
)
dataset_runperiod_simplified_1.format_table(
type_of_table='custom',
custom_cols=[
'Building_Total_Cooling Energy Demand (kWh/m2) (summed)',
'Building_Total_Heating Energy Demand (kWh/m2) (summed)',
]
)
dataset_runperiod_simplified_1.wrangled_table(
reshaping='pivot',
vars_to_gather=['ComfMod'],
baseline='CM_0',
comparison_mode=['baseline compared to others'],
comparison_cols=['relative', 'absolute']
)
No zones have been excluded from level computations.
All CSVs are for present scenario.
C:\users\sanga\appdata\local\programs\python\python39\lib\site-packages\accim\data\postprocessing\main.py:1684: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.df['col_to_pivot'] = 'temp'
C:\users\sanga\appdata\local\programs\python\python39\lib\site-packages\accim\data\postprocessing\main.py:1697: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self.df['col_to_pivot'] = wrangled_df_pivoted['col_to_pivot']
C:\users\sanga\appdata\local\programs\python\python39\lib\site-packages\accim\data\postprocessing\main.py:1777: FutureWarning: The provided callable <function sum at 0x000001B0A2D75E50> is currently using DataFrameGroupBy.sum. In a future version of pandas, the provided callable will be used directly. To keep current behavior pass the string "sum" instead.
wrangled_df_pivoted = wrangled_df_pivoted.pivot_table(
You can see below the resulting table is exactly the same:
[33]:
dataset_runperiod_simplified_1.wrangled_df_pivoted
[33]:
| col_to_pivot | CM_0 | CM_3 | 1-(CM_0/CM_3) | CM_3 - CM_0 |
|---|---|---|---|---|
| Building_Total_Cooling Energy Demand (kWh/m2) (summed) | 66.51 | 26.77 | -1.48 | -39.74 |
| Building_Total_Heating Energy Demand (kWh/m2) (summed) | 547.22 | 149.52 | -2.66 | -397.70 |
You can finally export the table as xlsx format:
[34]:
dataset_runperiod_simplified_1.wrangled_df_pivoted.to_excel('building_energy_demand.xlsx')
Let’s delete it now:
[35]:
new_files = [i for i in os.listdir() if i not in previous_files]
for i in new_files:
os.remove(i)